Physical Coherent Motion Generation
Case1


Case2


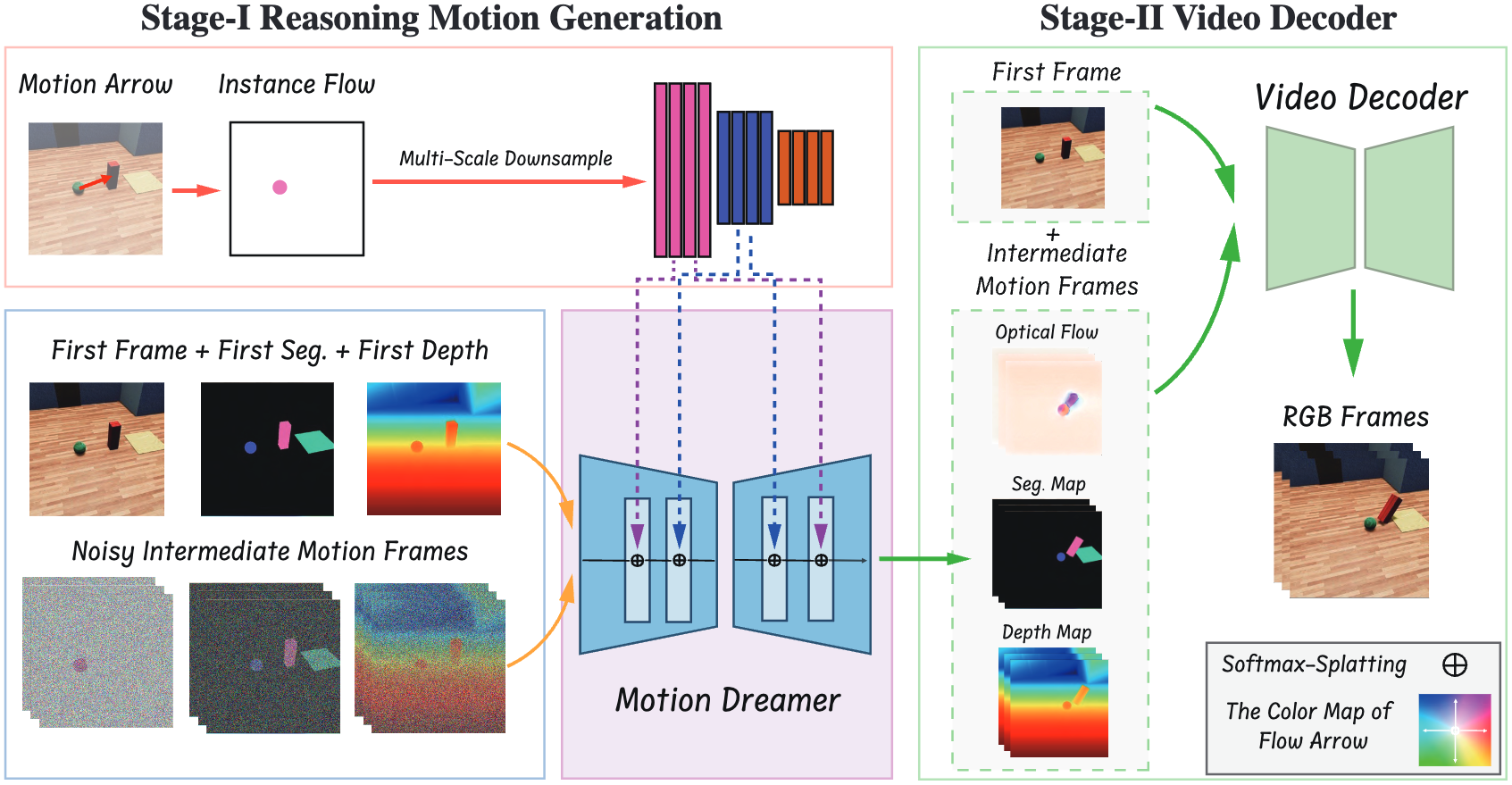
Recent numerous video generation models, also known as world models, have demonstrated the ability to generate plausible real-world videos. However, many studies have shown that these models often produce motion results lacking logical or physical coherence. In this paper, we revisit video generation models and find that single-stage approaches struggle to produce high-quality results while maintaining coherent motion reasoning. To address this issue, we propose Motion Dreamer, a two-stage video generation framework. In Stage I, the model generates an intermediate motion representation-such as a segmentation map or depth map-based on the input image and motion conditions, focusing solely on the motion itself. In Stage II, the model uses this intermediate motion representation as a condition to generate a high-detail video. By decoupling motion reasoning from high-fidelity video synthesis, our approach allows for more accurate and physically plausible motion generation. We validate the effectiveness of our approach on the Physion dataset and in autonomous driving scenarios. For example, given a single push, our model can synthesize the sequential toppling of a set of dominoes. Similarly, by varying the movements of ego-cars, our model can produce different effects on other vehicles. Our work opens new avenues in creating models that can reason about physical interactions in a more coherent and realistic manner.
/case1/Mofa_action1_prompt.png)
/case1/Ours_action1_prompt.png)
/case1/Mofa_action2_prompt.png)
/case1/Ours_action2_prompt.png)
/case2/Mofa_prompt.png)
/case2/Ours_prompt.png)
@article{xu2024motion,
title={Motion Dreamer: Realizing Physically Coherent Video Generation through Scene-Aware Motion Reasoning},
author={Xu, Tianshuo and Chen, Zhifei and Wu, Leyi and Lu, Hao and Chen, Yuying and Jiang, Lihui and Liu, Bingbing and Chen, Yingcong},
journal={arXiv preprint arXiv:2412.00547},
year={2024}
}